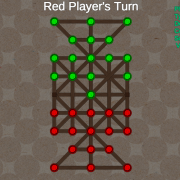
We invite you to play the web-based Sholo Guti (Bead 16) game built by our own Samin Bin Karim, an CSE undergrad from IUB and intern at AGenCy Lab. It is in its early state of development but playable.
Samin used Unity3D and RL-Agents with the aim to create a platform that could be used to train and test state-of-the art Reinforcement Learning Algorithms in an indigenous game that has almost no prior work done. The aim was to create an environment that can be accessed using python to enable easier training while also being a game playable with trained agents on multiple platforms.
Sholo Guti poses an interesting challenge to AI with a state space complexity of 10^17, which is comparable to the state space complexity 10^18 of popularly researched games like Checkers.
Firstly, Alpha-Beta MinMax search was implemented for the game in order to have a baseline against which to gauge the performance of the RL Agents and also to train RL Agents against it. Samin trained agents using two state-of-the art Reinforcement Learning Algorithms, Proximal Policy Optimization (PPO) and Soft Actor Critic (SAC). The agents were trained against MinMax opponents and against each other. The famous Open AI Five that defeated Dota 2 champions in 2019 was using an implementation of the PPO algorithm that had been adapted for training over large scale distributed systems.
After some limited training using very small networks (64 x 64), two fully connected layers, he managed to weakly solve the game. Both agents trained with PPO and SAC, managed to learn rudimentary defensive strategies for the initial phase of the game. The trained agents were able to achieve high win-rates against shallow searching Alpha Beta MinMax agents. However, MinMax Agents searching deeper still outperform this RL agent. He is working on training better RL agents.
We would appreciate your comments and suggestions about the game. You can check it out at https://saminbinkarim.itch.io/sholo-guti-project